Já aconteceu de você estar fazendo um trabalho no computador e começar a criar arquivos com esses nomes?
trabalho.txt trabalho-2.txt trabalho-3.txt trabalho-3-final.txt trabalho-3-final2.txt trabalho-3-final-agora-vai.txt trabalho-3-final-agora-vai2.txt trabalho-3-final-agora-vai-com-conclusao.txt trabalho-3-final-agora-vai-final-mesmo.txt
Já parou para pensar do porquê disso acontecer? Por que fazemos essa “bagunça” com os arquivos? O que acontece é que estamos tentando versionar o nosso trabalho. Ou seja, conforme ele vai sendo feito, algumas partes podem mudar, mas temos medo de apagar alguma coisa e depois se arrepender. Como vou voltar aquela parte toda que mudei porque achei que ia ficar melhor de outro jeito, mas não ficou? Por isso, acabamos fazendo uma cópia do arquivo (como se fosse um “backup”) e continuamos o trabalho em um novo arquivo, com um novo nome, nossa nova “versão“.
Talvez possa existir outros motivos… Uma vez fiz um trabalho (freela) de programação para um determinada empresa onde o processo das tarefas era:
- Faz download dos arquivos que estão no servidor;
- Desenvolve a tarefa, criando, removendo e/ou alterando os arquivos;
- Faz upload dos arquivos que mexeu, mas, antes, faça uma cópia do arquivo no servidor, renomeando para arquivo-data-da-alteração.
Que coisa, hein? O servidor ficava com um monte de cópias de “backups”. Mas, o pior não era isso! Certo dia, completei uma tarefa que foi devidamente auditada pelo coordenador do projeto e considerada homologada, pronta. Dois dias depois, ele entrou em contato comigo dizendo que a funcionalidade estava com problema. Bom, fui ver o arquivo que estava no servidor e, pasmem, não encontrei as alterações que eu havia feito no outro dia! Sabem o que aconteceu? Um outro programador da equipe havia feito o upload do mesmo arquivo com as alterações dele, em uma cópia do arquivo que não tinha as minhas alterações. Culpa dele? Não! Culpa do processo que não usava uma ferramenta capaz de lidar com essas situações.
Ferramentas de Controle de Versões
Se você já passou por alguma situação similar às que eu descrevi, o que você precisa é de uma ferramenta de controle de versões. Elas permitem que você tenha diversas versões dos seus arquivos, mas sem criar essa bagunça de nomes. Em qualquer momento, você pode ver um histórico de alterações e até mesmo recuperá-las. Além disso, elas permitem o trabalho em equipe, conciliando e combinando arquivos que foram alterados ao mesmo tempo!
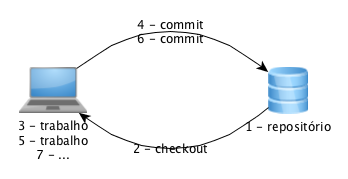
Basicamente, essas ferramentas funcionam da seguinte forma: cria-se um repositório de arquivos centralizado que será onde vão ficar os arquivos do seu projeto/trabalho. Quando você precisar trabalhar com esses arquivos, você faz o que chamamos de checkout deles, ou seja, a ferramenta faz uma cópia deles no seu computador. Em seguida, você desenvolve suas atividades, criando, removendo e/ou alterando os arquivos. Quando acabar, você envia essas modificações para o repositório por meio do que chamamos de commit, ou seja, a ferramenta irá controlar essas alterações no repositório, criando versões.
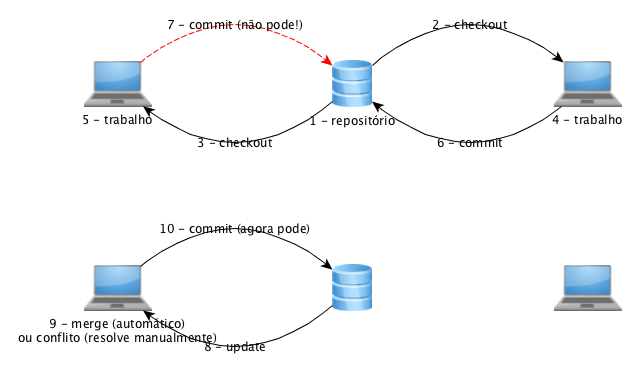
Pode ser que você esteja trabalhando e equipe… E, o que acontece quando outra pessoa fez um commit antes de você? Simples! A ferramenta detecta isso e não deixa você enviar suas alterações. Antes, você deve atualizar seus arquivos com as alterações que existem no repositório. Medo de perder o que você fez? Que nada! A ferramenta irá combinar os seus arquivos com os arquivos que estão no repositório. É o que chamamos de merge. Algumas vezes, a ferramenta não consegue completar essa operação por causa de algum conflito entre as modificações. Não se preocupe. Ela mostra onde estão esses conflitos para que você possa resolvê-los. Após seus arquivos estarem sincronizados, você pode, finalmente, enviar as suas alterações mais recentes.
Professor! Gostei dessa ferramenta!!! Qual posso usar?
Bom, você tem algumas opções disponíveis, sendo as mais conhecidas o CVS e o SVN.
Centralizado ou Distribuído?
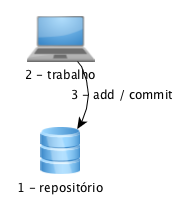
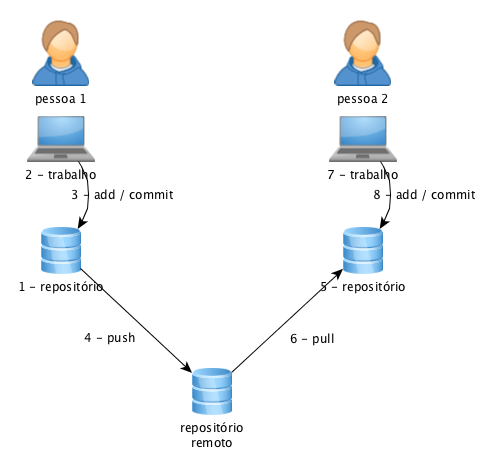
Mas, elas já estão um pouco defasadas. Esse modelo centralizado traz um pequeno problema de que, para que você possa usar a ferramenta, você deve estar conectado na rede, com possibilidade de se comunicar com o repositório. Existe um outro modelo, chamado distribuído que permite o versionamento sem uma conexão de rede, pois o repositório fica junto do seu diretório de trabalho. Nesse caso, o fluxo de trabalho sofre uma pequena simplificação: você cria o repositório, trabalha e faz commits (indicando, antes, quais os arquivos serão versionados).
Mas, e o trabalho em equipe? Como será feito se o repositório está na sua máquina? Bom, nesse caso, a gente faz upload (push) e download (pull) dos arquivos entre os repositórios, sendo comum a criação de um repositório remoto para centralizar os arquivos. O processo de merge e resolução de conflitos permanece o mesmo.
Professor! Gostei mais ainda dessa ferramenta!!! Como posso fazer para começar a usar?
Nesse caso, as ferramentas mais conhecidas são o Git e o Mercurial, sendo o Git ainda mais famoso, na minha opinião, por causa de um site chamado GitHub. Ele é uma rede social para desenvolvedores onde você pode criar repositórios de códigos que ficam disponíveis para que outras pessoas possam contribuir com seus projetos (e vice-versa). 🙂
Git
Para você começar a dar os primeiros passos com o Git, a primeira coisa a fazer é instalá-lo. Vá até o seu site e faça o download específico para seu sistema operacional.
Configurando
Após a instalação, a primeira coisa que você deve fazer é configurar o Git. Para isso, abra uma janela de terminal (no Windows, você deve escolher o programa “Git Bash“) e digite os seguintes comandos:
git config --global user.name "Seu Nome" git config --global user.email "seu@email.com"
Note que você fará isso apenas uma vez! A partir daí, o Git irá usar essas informações para registrar quem foi que fez as alterações nos arquivos.
Criando um Repositório
Criar um repositório no Git é muito simples: basta criar um novo diretório onde você irá desenvolver seu trabalho, entrar dentro dele e digitar o seguinte comando: git init.
Segue a sequência completa de comandos:
mkdir meu-projeto (irá criar o diretório) cd meu-projeto (irá entrar dentro do diretório) git init (irá criar o repositório git)
Se você estiver no Windows, crie uma pasta normalmente, usando o Windows Explorer e, depois, clique com o botão direito nela. Irá aparecer a opção “Git Bash Here/Aqui“. Clique nela e um terminal irá abrir já dentro do diretório, bastando digitar o comando git init.
Vale notar que você irá iniciar o repositório apenas uma vez para cada diretório de projeto que você quer versionar. Repetindo: um repositório para cada projeto.
Fluxo de Trabalho
Uma vez que você já tenha um repositório, basta começar a trabalhar, criando, removendo e alterando arquivos. Quando quiser versionar, você irá usar os seguintes comandos:
git add arquivo (para cada arquivo criado, removido ou alterado) git commit -m "Mensagem com descrição do commit" (envia para o repositório)
Note que o comando git add deve ser feito para cada arquivo a ser versionado. Caso você queira que todos os arquivos criados, removidos ou alterados sejam versionados, você pode usar o seguinte comando:
git add . (versiona todos os arquivos criados, removidos ou alterados)
Talvez você esteja se perguntando do porquê de ter dois comandos para fazer o commit. Bom, a ideia do comando add é poder controlar quais conjuntos de modificações serão enviadas para o repositório para serem versionadas. Em outras palavras, quais alterações que, juntas, são descritas pela mensagem do commit.
Para ficar ainda mais claro, imagine que você esteja programando e tenha 2 tarefas para cumprir. Aí, durante a execução da tarefa 1 você mexeu nos arquivos A e B e durante a execução da tarefa 2 você mexeu nos arquivos C e D. Nesse momento você decide fazer o versionamento do seu trabalho. Como fazer para ter dois commits? Um para a tarefa 1 e outro para a tarefa 2, já que você está com quatro alterações no seu diretório de trabalho? É nesse ponto que entra o comando add. Veja a sequência de comandos para fazer esses dois commits:
git add A git add B git commit -m "tarefa 1" git add C git add D git commit -m "tarefa 2"
Obviamente, se você mexeu no arquivo A tanto para a tarefa 1 quanto para a tarefa 2, não terá jeito de fazer dois commits. Nesse caso, eu faria o add em todos os arquivos e na mensagem do commit escreveria “tarefas 1 e 2”. Por isso, é aconselhável fazer um commit a cada finalização de tarefa. Sem dúvida, um treino de disciplina! 😉
Os Três Estados
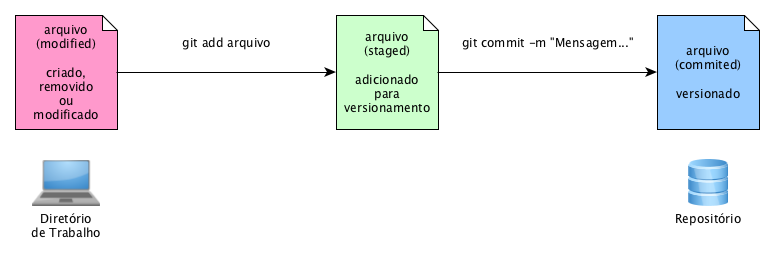
É interessante você saber que, no jargão do Git, os arquivos estão sempre em um de três estados:
- Modified (modificado): são os arquivos que você criou, removeu ou alterou.
- Staged (observado, em tradução livre): são os arquivos que serão versionados ao se fazer commit.
- Commited (versionado, em tradução livre): são os arquivos armazenados no repositório.
O comando git status permite que você veja o que está acontecendo a cada momento. Veja um exemplo, copiado diretamente do meu terminal:
Lester:~ ramonchiara$ mkdir projeto Lester:~ ramonchiara$ cd projeto Lester:projeto ramonchiara$ git init Initialized empty Git repository in /Users/ramonchiara/projeto/.git/ Lester:projeto ramonchiara$ git status On branch master Initial commit nothing to commit (create/copy files and use "git add" to track) Lester:projeto ramonchiara$ touch A (criação do arquivo A) Lester:projeto ramonchiara$ git status On branch master Initial commit Untracked files: (use "git add ..." to include in what will be committed) A nothing added to commit but untracked files present (use "git add" to track) Lester:projeto ramonchiara$ git add A Lester:projeto ramonchiara$ git status On branch master Initial commit Changes to be committed: (use "git rm --cached ..." to unstage) new file: A Lester:projeto ramonchiara$ git commit -m "commit de A" [master (root-commit) 3d9f31b] commit de A 1 file changed, 0 insertions(+), 0 deletions(-) create mode 100644 A Lester:projeto ramonchiara$ git status On branch master nothing to commit, working tree clean Lester:projeto ramonchiara$
Note que ele é seu amigo! Em muitos momentos ele até diz para você qual o próximo comando que você pode ou deveria fazer! 🙂
Histórico de Commits
Bom, uma vez que você já trabalhou um monte e fez um monte de commits, é possível que você queira ver o histórico das suas alterações. E, para fazer isso, basta executar o seguinte comando:
git log
Ele irá mostrar um registro parecido com este (copiado diretamente do meu terminal):
Lester:projeto ramonchiara$ git log
commit 2a13c0a4a98a55633d5bda966471197112b327bd
Author: Ramon Chiara <ramonchiara@gmail.com>
Date: Sun Mar 5 22:40:17 2017 -0300
adição de outra linha de texto
commit e13431d48b7d4996e0a5d4493dafa5d15feec6cd
Author: Ramon Chiara <ramonchiara@gmail.com>
Date: Sun Mar 5 22:40:03 2017 -0300
adição de uma linha de texto
commit 3d9f31bcec76309d1e6c554ba16131ea46b33465
Author: Ramon Chiara <ramonchiara@gmail.com>
Date: Sun Mar 5 22:30:14 2017 -0300
commit de A
Note que este comando mostra apenas as mensagens que você colocou no momento do commit. Caso queira ter um pouco mais de detalhes, você pode usar o comando:
git show ou git show número-do-commit
Ele irá mostrar não só a mensagem do commit, mas o que exatamente você fez nele, conforme o exemplo abaixo (copiado diretamente do meu terminal):
Lester:projeto ramonchiara$ git show
commit 2a13c0a4a98a55633d5bda966471197112b327bd
Author: Ramon Chiara <ramonchiara@gmail.com>
Date: Sun Mar 5 22:40:17 2017 -0300
adição de outra linha de texto
diff --git a/A b/A
index ece0ad7..453a995 100644
--- a/A
+++ b/A
@@ -1 +1,2 @@
Uma linha de texto
+Outra linha de texto
Note que, se você não colocar qual número do commit você quer ver, ele irá mostrar o do último commit. Número do commit??? Sim! Aquele número gigante que aparece ao lado de cada commit quando você executa o comando git log. Quando você começar a ficar “craque” no git, você irá descobrir outras utilidades para eles! 🙂
Repositórios Remotos
Para finalizar este artigo de “primeiros passos”, eu não podia deixar de te ensinar os comandos para que você trabalhe com repositórios remotos. Afinal, como você vai trabalhar junto com sua equipe sem isso, não é mesmo?
De forma a fazermos um exemplo desse tópico, iremos recorrer ao GitHub. Caso vocâ ainda não tenha uma conta lá, crie uma e, logo em seguida, vá neste link e clique em ![]() . 😉 Brincadeiras à parte, crie um repositório lá, usando um dos seguites botões, dependendo de qual página você se encontra lá dentro:
. 😉 Brincadeiras à parte, crie um repositório lá, usando um dos seguites botões, dependendo de qual página você se encontra lá dentro:
 ou
ou ![]()
Após isso, uma tela com vários campos para preenchimento irá aparecer. Entre com o nome do seu repositório e, opcionalmente, uma descrição, conforme exemplo abaixo:
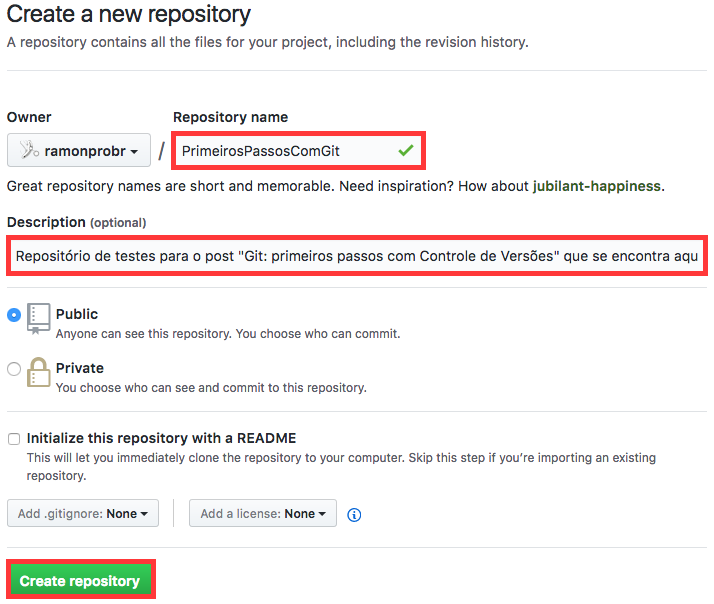
Ao clicar no botão ![]() , o GitHub irá criar um repositório para você lá nos servidores dele! A tela seguinte irá mostrar o seu endereço (URL), que você irá precisar para enviar (push) suas alterações para lá ou receber (pull) as colaborações que sua equipe fez. Veja o exemplo:
, o GitHub irá criar um repositório para você lá nos servidores dele! A tela seguinte irá mostrar o seu endereço (URL), que você irá precisar para enviar (push) suas alterações para lá ou receber (pull) as colaborações que sua equipe fez. Veja o exemplo:
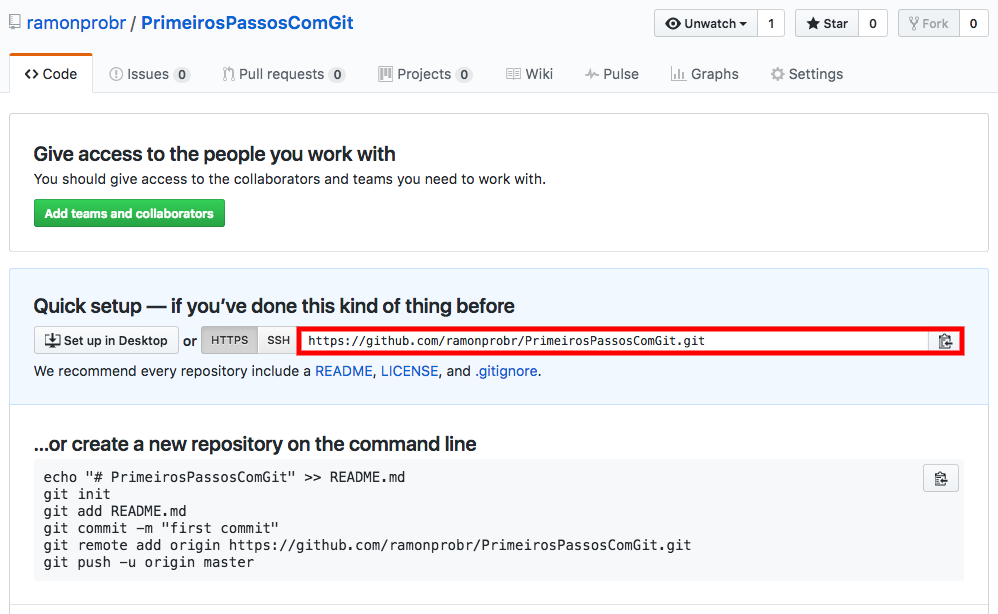
Uma vez que você tenha criado o repositório no GitHub, você deve “avisar” o seu repositório local de que existe esse repositório remoto. Para fazer isso, use o seguinte comando:
git remote add nome-do-repositório url-do-repositório
É comum o uso de origin para o nome do repositório, indicando o repositório origem das contribuições, por assim dizer. Levando em conta o nosso exemplo, o comando ficaria dessa forma:
git remote add origin https://github.com/ramonprobr/PrimeirosPassosComGit.git
Note que você fará isso apenas uma vez! A partir daí, o Git irá usar essas informações para enviar e receber as alterações desse repositório remoto.
Enviando Alterações
Agora que seu repositório local já sabe da existência do repositório remoto origin, para enviar seus commits para lá, use o seguinte comando:
git push origin master
Ou seja, push (empurre, envie) para o origin as alterações que estão em master. O master eu explico em um outro artigo o que é. Mas, só para você não ficar tããã curioso, ele é o nosso branch principal.
Note que o Git, neste momento, irá pedir seu login e senha no GitHub. Dessa forma, você está indicando que tem permissão de “escrever” no respositório de lá. Já pensou se não fosse assim? Outras pessoas poderiam fazer uma bagunça nos seus arquivos!
Bom, após você ter enviado alguns commits, a página do seu repositório no GitHub já deve ter mudado para algo assim:
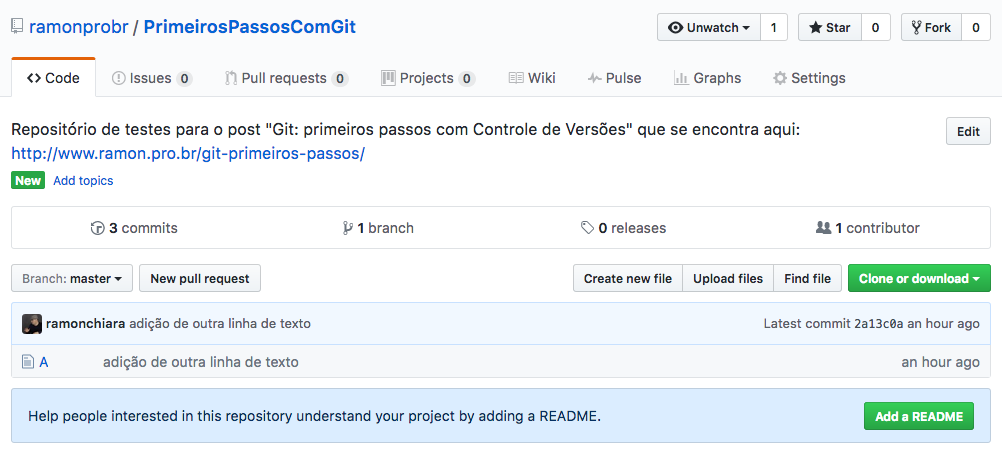
Aconselho você a fazer um pequeno passeio pelas diversas abas e links. Tem muita coisa interessante por ali. Uma delas é que você pode editar os arquivos diretamente pelo GitHub. Não que você deva trabalhar dessa forma, mas, em caso de alguma emergência, é possível fazê-lo.
No nosso exemplo, eu irei editar o arquivo A, como se outra pessoa da equipe tivesse feito uma alteração. Para isso, eu clico no link correspondente ao arquivo A e, depois, no botão ![]() . Assim, uma tela com o conteúdo do arquivo irá aparecer de forma que eu possa editá-lo. Faço algumas alterações, escrevo uma mensagem no campo de mensagem do commit e, depois, clico no botão
. Assim, uma tela com o conteúdo do arquivo irá aparecer de forma que eu possa editá-lo. Faço algumas alterações, escrevo uma mensagem no campo de mensagem do commit e, depois, clico no botão ![]() , conforme você pode ver abaixo:
, conforme você pode ver abaixo:
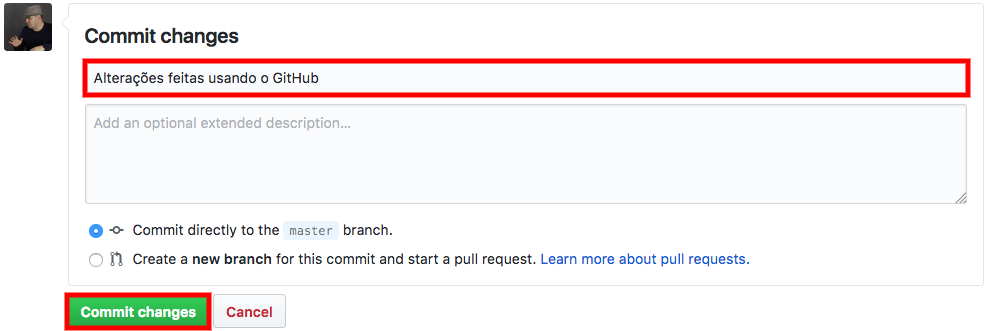
Note que eles foram bem precisos ao escrever “Commit changes” no botão ao invés de “Save”. Isso porque, quando gravamos as alterações pelo GitHub, o que estamos fazendo, na verdade, é um commit lá.
Recebendo Alterações
Hum! Mas, se o commit foi feito lá, como fica o nosso repositório local? Como faço para trazer essas alterações? Simples… Basta fazer o comando oposto ao do push que é pull:
git pull origin master
Ou seja, pull (puxe, traga) de origin as alterações e coloque-as em master. Veja o resultado real (copiado diretamente do meu terminal):
Lester:projeto ramonchiara$ git status On branch master nothing to commit, working tree clean Lester:projeto ramonchiara$ git pull origin master remote: Counting objects: 3, done. remote: Compressing objects: 100% (2/2), done. remote: Total 3 (delta 0), reused 0 (delta 0), pack-reused 0 Unpacking objects: 100% (3/3), done. From https://github.com/ramonprobr/PrimeirosPassosComGit * branch master -> FETCH_HEAD 2a13c0a..492a5db master -> origin/master Updating 2a13c0a..492a5db Fast-forward A | 1 + 1 file changed, 1 insertion(+) Lester:projeto ramonchiara$ cat A Uma linha de texto Linha adicionada pelo "editor" do GitHub. Outra linha de texto Lester:projeto ramonchiara$
Como podemos ver (no finalzinho, no comando cat A), o conteúdo do arquivo agora está com as alterações que eu havia feito no GitHub.
Conflitos
Caso você tenha alterado o arquivo no GitHub e, também no repositório local, pode acontecer um conflito, ou seja, uma situação em que o Git não consegue saber o que fazer. Isso acontece, por exemplo, quando a mesma linha de texto é alterada. Vamos ver isso acontecendo e como resolver:
- Altero o arquivo no GitHub, modificando a primeira linha para Uma linha de texto alterada no GitHub., como se uma outra pessoa da equipe tivesse feito essa alteração.
- Altero o arquivo no meu repositório local, modificando a mesma linha para Uma linha de texto alterada localmente..
- Faço o commit normalmente:
Lester:projeto ramonchiara$ git add A Lester:projeto ramonchiara$ git commit -m "Primeira linha de texto alterada localmente." [master 4dfeba8] Primeira linha de texto alterada localmente.
- Tento fazer um push, mas o Git me avisa que há modificações no repositório remoto (note a mensagem rejected):
Lester:projeto ramonchiara$ git push origin master To https://github.com/ramonprobr/PrimeirosPassosComGit.git ! [rejected] master -> master (fetch first) error: failed to push some refs to 'https://github.com/ramonprobr/PrimeirosPassosComGit.git' hint: Updates were rejected because the remote contains work that you do hint: not have locally. This is usually caused by another repository pushing hint: to the same ref. You may want to first integrate the remote changes hint: (e.g., 'git pull ...') before pushing again. hint: See the 'Note about fast-forwards' in 'git push --help' for details.
- Tenho que atualizar meu repositório local fazendo um pull:
Lester:projeto ramonchiara$ git pull origin master remote: Counting objects: 3, done. remote: Compressing objects: 100% (2/2), done. remote: Total 3 (delta 0), reused 0 (delta 0), pack-reused 0 Unpacking objects: 100% (3/3), done. From https://github.com/ramonprobr/PrimeirosPassosComGit * branch master -> FETCH_HEAD 492a5db..39b0aaf master -> origin/master Auto-merging A CONFLICT (content): Merge conflict in A Automatic merge failed; fix conflicts and then commit the result.
- Deu conflito! Note a mensagem conflict!
- Resolvo o conflito, editando os arquivos nessa situação e removendo as marcações que o Git deixou lá. Essas marcações são do tipo:
<<<<<<< conteúdo local ======= conteúdo remoto >>>>>>>Ou seja, ele mostra o que tem no repositório local e o que tem no repositório remoto para que você possa decidir o que fazer… Observe como ficou o arquivo que está com conflito no nosso exemplo:
<<<<<<< HEAD Uma linha de texto alterada localmente. ======= Uma linha de texto alterada no GitHub. >>>>>>> 39b0aaff85c8bfad17773137b22052a71b87ec58 Linha adicionada pelo "editor" do GitHub. Outra linha de texto
De novo, note que você deve decidir qual será o conteúdo final do seu arquivo. Neste exemplo, eu decidi deixar assim:
Uma linha de texto alterada. Linha adicionada pelo "editor" do GitHub. Outra linha de texto
- Faço um commit para finalizar a resolução do conflito:
Lester:projeto ramonchiara$ git add A Lester:projeto ramonchiara$ git commit -m "conflito resolvido" [master 90dde3f] conflito resolvido
- Finalmente, posso enviar minhas alterações para o repositório remoto:
Lester:projeto ramonchiara$ git push origin master Counting objects: 6, done. Delta compression using up to 8 threads. Compressing objects: 100% (4/4), done. Writing objects: 100% (6/6), 652 bytes | 0 bytes/s, done. Total 6 (delta 0), reused 0 (delta 0) To https://github.com/ramonprobr/PrimeirosPassosComGit.git 39b0aaf..90dde3f master -> master
Você pode ver o resultado desse passo-a-passo no histórico do arquivo A! Parece complicado, mas, com o tempo, você fica craque em se virar nessas situações apresentadas, tá? 😉
Trabalhando em Equipe
Agora que você já sabe enviar (push) e receber (pull) alterações de um repositório remoto no GitHub, preciso te dizer que, para trabalhar com uma equipe, é necessário que você o configure para isso. Lembra que quando você envia os commits (push) ele pede o seu login e senha? Pois então… Mesmo que a outra pessoa da equipe tenha uma conta no GitHub, o login dela não vai ter acesso de escrita no seu repositório. A menos que você a coloque como colaboradora do seu projeto. Para fazer isso, vá na página do seu repositório, clique na aba “Settings” e, depois, em “Collaborators“. Nessa página, você pode adicionar o login dela e dos outros membros da equipe. A partir daí, eles terão direito de escrita neste seu repositório no GitHub e poderão colaborar com o seu projeto.
Outro ponto é: como as pessoas da sua equipe irão trazer o repositório inteiro para as suas máquinas, na primeira vez? Simples! Vamos relembrar o processo como um todo?
mkdir projeto (cria um diretório para o projeto que vou colaborar)
cd projeto (entro dentro do diretório)
git init (crio o repositório git)
git remote add nome-do-repositório url-do-repositório ("aviso" o git que existe um repositório remoto)
git pull nome-do-repositório master (trago as alterações do repositório remoto para o meu repositório local)
Muitos comandos, não é mesmo? Por isso que, se o que você quer é apenas fazer uma cópia do repositório remoto, um clone, o git tem um comando mais fácil:
git clone url-do-repositório
Esse comando irá fazer todo o processo mostrado anteriormente, inclusive a criação do diretório e a configuração do repositório remoto. Ou seja, depois de executá-lo, basta entrar no diretório, começar a trabalhar e a fazer commits! 🙂 Não se esqueça de fazer o push das alterações para que as outras pessoas da equipe possam receber suas colaborações!
Atenção: existe uma outra forma, inclusive mais usual, de se trabalhar em equipes usando o GitHub como repositório remoto: por meio da clonagem dos repositórios. Lá no GitHub, o comando clone é feito por meio do botão fork. E, o envio das alterações é feito por meio de um botão chamado pull request. Deixarei para explicar isso em mais detalhes num artigo futuro.
Conclusão
Talvez esse tenha sido o artigo mais longo que tenha escrito aqui! 🙂 Espero que ele possa ter esclarecido a utilização básica e, principalmente, prática do Git e do GitHub.
Ah! Caso você use um IDE como o NetBeans, Eclipse, Visual Studio Code, entre outros, provavelmente não irá usar o Git no terminal! Esses ambientes costumam ter integração com as ferramentas de controle de versões, facilitando sua vida. No entanto, essas facilidades têm limites e, muitas vezes, você vai acabar indo para a famosa “linha de comando”. Pior (ou melhor?)! Vai achar mais fácil!
Para finalizar, como é de costume, peço que deixe um comentário com seu feedback. Curta o artigo e compartilhe! Porquê? Porque você pode! 🙂 E, porque assim saberei que estou gerando valor com esses conteúdos que coloco aqui!
Um grande abraço e até breve!
Ótimo artigo professor, me ajudou muito. Passo a passo feito de exemplos, facilitando e clareando as dúvidas de todos.
Oi, Guilherme!
Que bom que ajudou! Fico muito feliz com isso!
Muito obrigado pelo seu feedback.
[]s, Ramon
explicação mais clara que essa não existe, obg professor !
Oi, Maycon!
Que bom que gostou!!! 🙂
Eu que agradeço! 😉
[]s
Ramon,
Faz poucos dias que estou aprendendo a utilizar o Git e, na busca de uma imagem ilustrativa para o arquivo que estou fazendo (estava!) tive a sorte de encontrar seu artigo.
Ele está muito bem estruturado e detalhado, vai ajudar demais quem está iniciando … e vc diz que isso são só os “primeiros passos”??? kkkk … muito bom man, grato pelo tempo e dedicação, sucesso!!!
Bruno,
Que bom que ajudou!
Fico muito feliz, de verdade!
Sucesso pra todos nós!
Grande abraço